Vision-Language-Action Models for Robotics:
A Review Towards Real-World Applications
IEEE Access 2025
- Kento Kawaharazuka(a)
- Jihoon Oh(a)
- Jun Yamada(b)
- Ingmar Posner(b)*
- Yuke Zhu(c)*
- (a) The University of Tokyo, (b) University of Oxford, (c) The University of Texas at Austin
- * Equal advising
 arXiv
arXiv
Overview
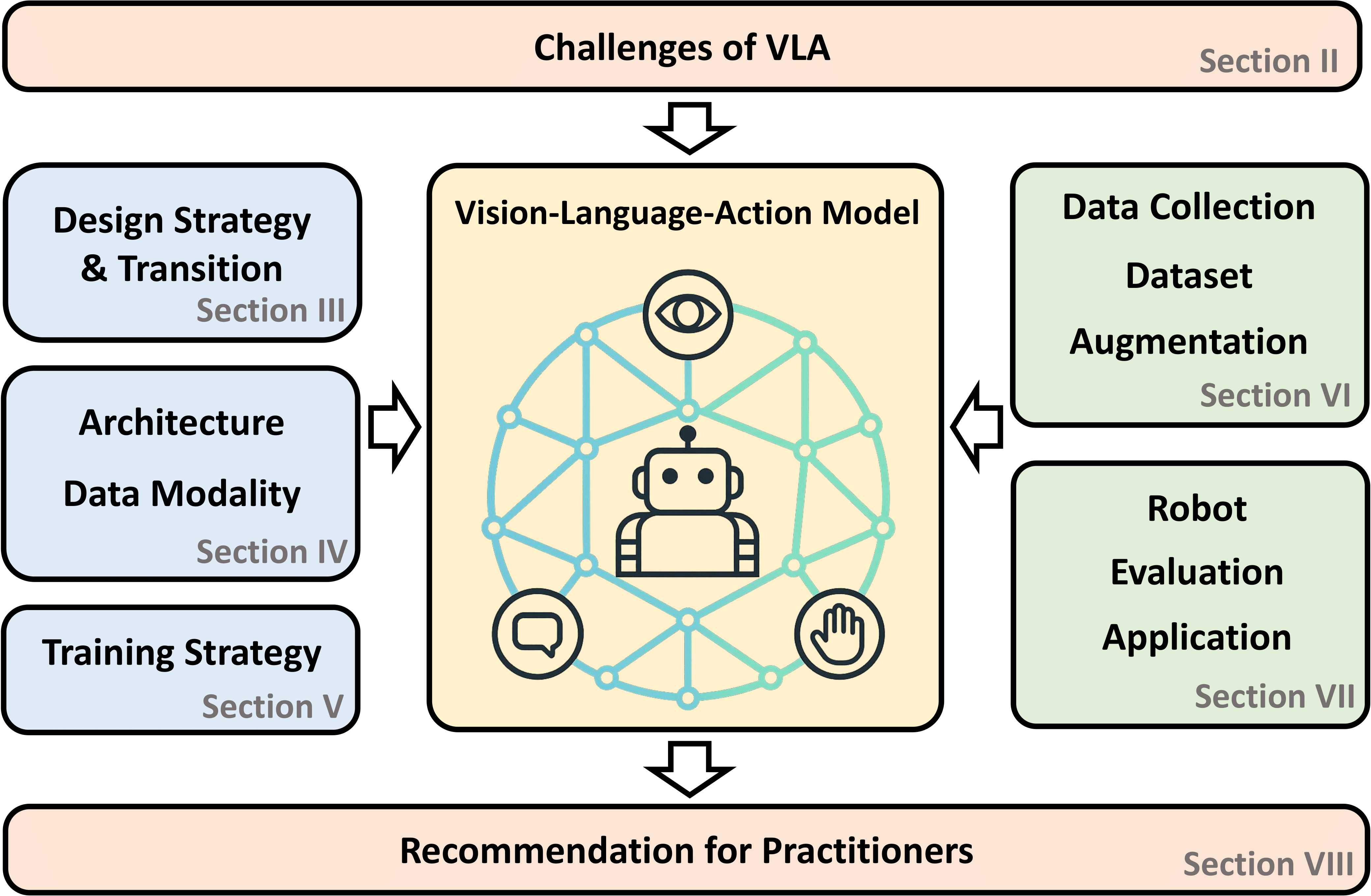
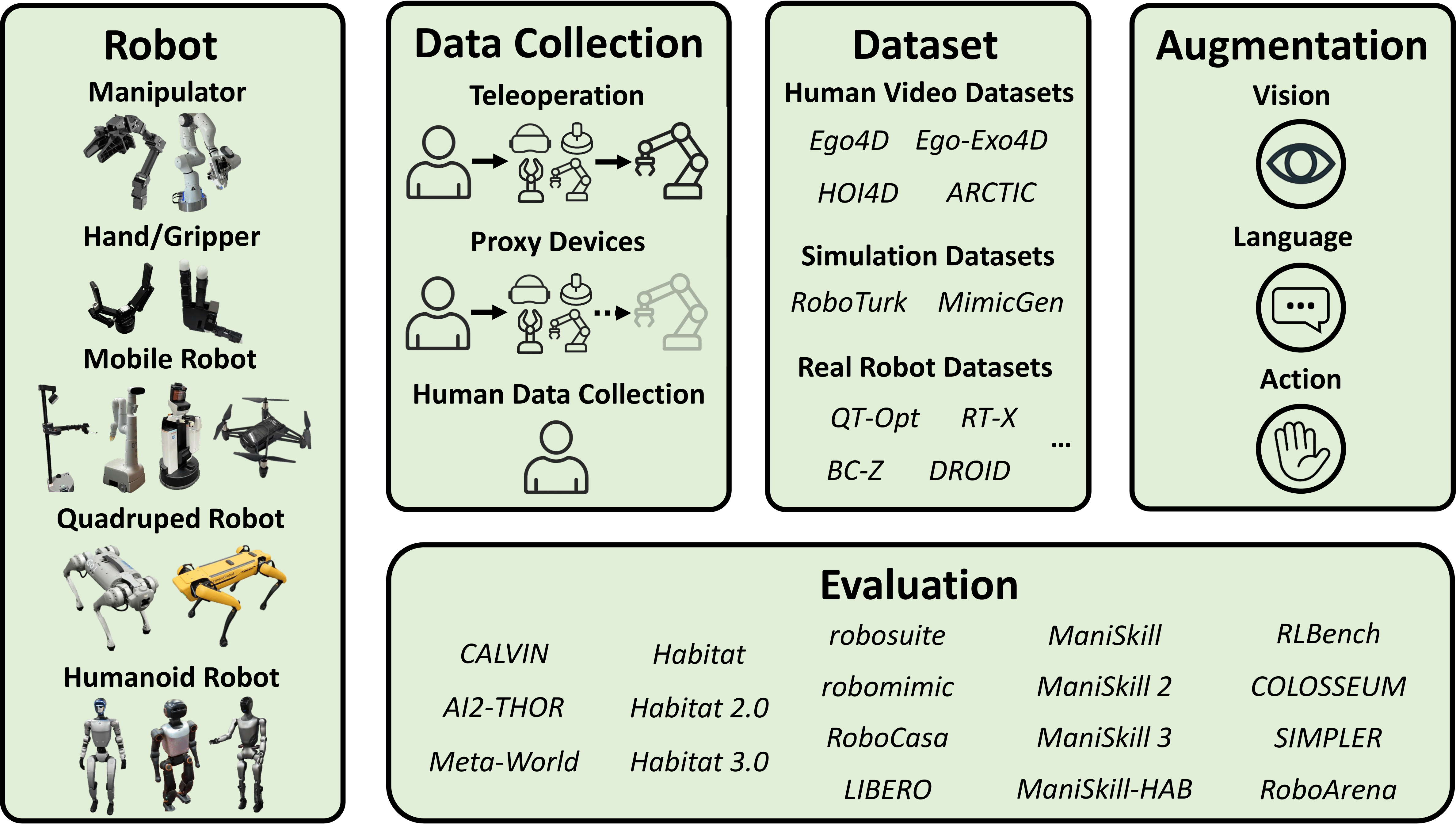
Amid growing efforts to leverage advances in large language models (LLMs) and vision-language models (VLMs) for robotics, Vision-Language-Action (VLA) models have recently gained significant attention. By unifying vision, language, and action data at scale, which have traditionally been studied separately, VLA models aim to learn policies that generalise across diverse tasks, objects, embodiments, and environments. This generalisation capability is expected to enable robots to solve novel downstream tasks with minimal or no additional task-specific data, facilitating more flexible and scalable real-world deployment. To better understand the foundations and progress towards this goal, this paper provides a systematic review of VLAs, covering their strategy and architectural transition, architectures and building blocks, modality-specific processing techniques, and learning paradigms. In addition, to support the deployment of VLAs in real-world robotic applications, we also review commonly used robot platforms, data collection strategies, publicly available datasets, data augmentation methods, and evaluation benchmarks. Throughout this comprehensive survey, this paper aims to offer practical guidance for the robotics community in applying VLAs to real-world robotic systems.
Interactive Survey Table
Explore our comprehensive database of VLA models. Use the filters below to search by category, task type, modality, or robot platform. Click on column headers to sort.
| Category | Abbreviation | Title | Conference | Paper | Website | Task | Domain | Robot | Training | Evaluation | Modality | Dataset | Backbone | Action Gen |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Loading CSV data... | ||||||||||||||
BibTeX
@article{kawaharazuka2025vla-survey,
author={Kento Kawaharazuka and Jihoon Oh and Jun Yamada and Ingmar Posner and Yuke Zhu},
journal={IEEE Access},
title={Vision-Language-Action Models for Robotics: A Review Towards Real-World Applications},
volume={13},
pages={162467--162504},
year={2025},
doi={10.1109/ACCESS.2025.3609980},
}
Contact
If you have any questions or suggestions, please feel free to contact Kento Kawaharazuka.